Benchmarking deep learning models
for predicting anticancer drug potency (IC50) with insights for medicinal chemists
https://www.nature.com/articles/s42004-026-01916-9
2026, nature communications chemistry(IF=6.2)
IC50 예측 모델 5가지(DeepCDR, DrugCell, PaccMann, Precily, and tCNN) 벤치마킹 논문 겸,
새로운 평가 지표를 제안한 논문. background 지식 보충하기 위함.
소분자 화합물의 IC50 예측( Potency, 효능)은 항암제 개발의 핵심( pivotal )이다. 본 연구는 표준화된 GDSC데이터베이스와 최근 공개된(published) 항암 화합물을 활용하여 IC50 예측하는 5개의 딥러닝 모델(DeepCDR, DrugCell, PaccMann, Precily, tCNN)를 단순 평균 기반의 Baseline모델과 비교 분석(벤칭마킹)했다.
실용성을 확보하기 위해 기존의 오차 지표에 percentage error, log error, three-sigma limit, 그리고 새롭게 제안한 Experimental Variability-Aware Prediction Accuracy statistic 등을 추가하여 분석을 보강했다. 모델은 random split 데이터와 unseen cell lines에서 좋은 성과를 냈지만 학습 되지않은 화합물에 대한 정확도가 급격히 감소했다. 모든 딥러닝 모델들은 비슷한 성능 추세를 보였지만, DeepCDR, DrugCell, tCNN은 대부분 테스트 시나리오에서 약간 우위를 점했다(held a slight edge in). 흥미롭게도 몇 딥러닝 알고리즘은 많은 테스트에서 baseline 모델 보다 유의미하게 뛰어난 성능을 보여주지 못했다. 화합물 및 세포주의 물리화학적( physicochemical )`생물학적인 특성에 따른 예측 오차 분석 결과,이들 간의 상관 관계가 약함을 확인했으며 이는 모델 성능 측면에서 아직 탐구되지 않은 영역이 존재함을 시사한다.
*내 모델도 비슷한 경향을 보임. 공통된 문제임을 확인함.
1. Background
- as the same drug can have widely varying IC50 across different cell lines
- e.g., the drug foretinib has an IC50 of 0.074 μM in the KU-812 cell line
whereas in the SW1417 cell line the same drug has an IC50 of 8.364 μM: > 100-fold difference,
- e.g., the drug foretinib has an IC50 of 0.074 μM in the KU-812 cell line
2. Overview of DL for drug potency prediction

3. Results 1. Performance evaluation of IC50
- figure3. Five-fold cross-validation(R: Random split, NCC: No Common Cell line, and NCD: No Common Drug)
- NCD: unseen cell line test set
- NCD: unseen drug test set
- the Pearson correlation coefficient (r), coefficient of determination (R2), and root-mean-squared error (RMSE) computed on ln(IC50)

결과 요약:
1. R split: r(0.81–0.88) 및 R² 값(0.63–0.77)과 낮은 RMSE(0.98–1.23)
2. NCC split: 모델 성능은 약간 저하되었습니다. 상관계수( r )(0.76~0.82), R² (0.56~0.67), RMSE(1.12~1.31)
- base line: r ~ 0.85, R² ~ 0.71, RMSE ~1.07을 달성하며 매우 우수한 성능을 보임
- tCNN이 가장 우수한 성적
- PaccMann과 DrugCell은 더 높은 MAPE 및 MALE 값과 더 큰 변동성을 보여 세포주의 생물학적 다양성에 민감함을 보임.
3. NCD split: 모든 모델의 성능이 급격히 저하
- baseline: 상관계수 (r) 와 R² 는 약 0 , RMSE는 약 2.23
- 대부분의 오류 지표에서 일부 딥러닝 모델의 성능은 기준선보다 떨어짐
- 해석 주의**
- r값(상관계수)이 높은데 왜 성능이 낮다고 하나요?
- r값은 경향성만 보기 때문. 실제값이 커질 때 예측값도 커지기만 하면 r은 높게나온다.
- 실제값은 1인데 예측값을 100으로 놓는 경우도 높게나온다는 뜻.
- 본문에서 이를 지적 "predicted $IC_{50}$ values being up to 9× different" 사실상 실용성 없는 예측값임!
- $R^2$가 음수
- "그냥 평균값으로 찍는 것보다도 훨씬 못 맞춘다"라는 뜻.
- MALE(Log Error)의 급증: 에러가 2배 늘어났다는 것은 실제 농도 단위에서는 어마어마한 차이임.
- r값(상관계수)이 높은데 왜 성능이 낮다고 하나요?
4. Materials and Method
- Baseline:
R (Random Split) Global Mean (전체 평균) 모든 약물-세포주 쌍의 IC50 값을 다 합쳐서 평균을 낸 단 하나의 값으로 모두 예측합니다. NCC (No Common Cell lines) Drug-wise Mean (약물별 평균) 특정 약물의 여러 세포주에 나타냈던 반응들의 평균을 구합니다. 즉, "이 약은 보통 이 정도 효과가 있더라"는 평균치로 예측합니다. NCD (No Common Drugs) Cell line-wise Mean (세포주별 평균) 특정 세포주의 여러 약물에 반응했던 평균을 구합니다. 즉, "이 암세포는 보통 약에 이 정도로 반응하더라"는 평균치로 예측합니다. - Compound properties:
- Four Lipinski parameters, namely molecular weight (MW), lipophilicity (clogP), number of hydrogen bond donors (HBD), and number of hydrogen bond acceptors (HBA), along with rotatable bond count (RotB) and the fraction of sp3-hybridized atoms (Fsp3), were selected as physicochemical properties for analysis
- 170가지 화합물 대상으로 분석 수행. ZINC15과 같은 데이터베이스 대부분 커버하는 양임.
- 이런 데이터도 활용해 특징값을 얻을 수 있구나~
- biological properties compounds
- The variation in prediction error corresponding to the target pathways of compounds

- 해당 실험이 흥미로웠으나, 결론은 미심쩍은 부분이 있음
- " 이전에 확립된 pIC 50 의 실험적 변동성 (0.853)을 고려할 때, 모델의 예측 정확도는 화합물의 표적 경로 전반에 걸쳐 상당한 편향을 보이지 않는다고 추론할 수 있다"
- 이 말은 곧 "모델이 완벽하게 맞히지는 못해도(Low Accuracy), 생물학적 데이터가 가진 태생적인 흔들림(Biological Noise)만큼만 틀리고 있으니, 나름대로 생물학적 규칙을 '이해'하고 있는 셈이다" 라고 주장하는 말임.
- MAPE란, 실제값 대비 오차가 몇 %나 나는가? 인데, 몇 %차이가 실제 농도값에서는 큰 차이가 날 수 있다는 점.
- 모델 편향일 수도 있다는 점. 이를 딱히 실험으로 증명하기보다는 해석을 긍정적으로 한것에 그친다는 점.
- 그래서 figure 5의 그림에서 딱히 인사이트를 얻을 것은 없었단점.(그냥 supplementary 에 그치지않았던..)
- The variation in prediction error corresponding to the target pathways of compounds
- Performance on novel anticancer compounds
- GDSC 프로토콜에 따라, 새로운 약물에 대해 실험하여 얻음.
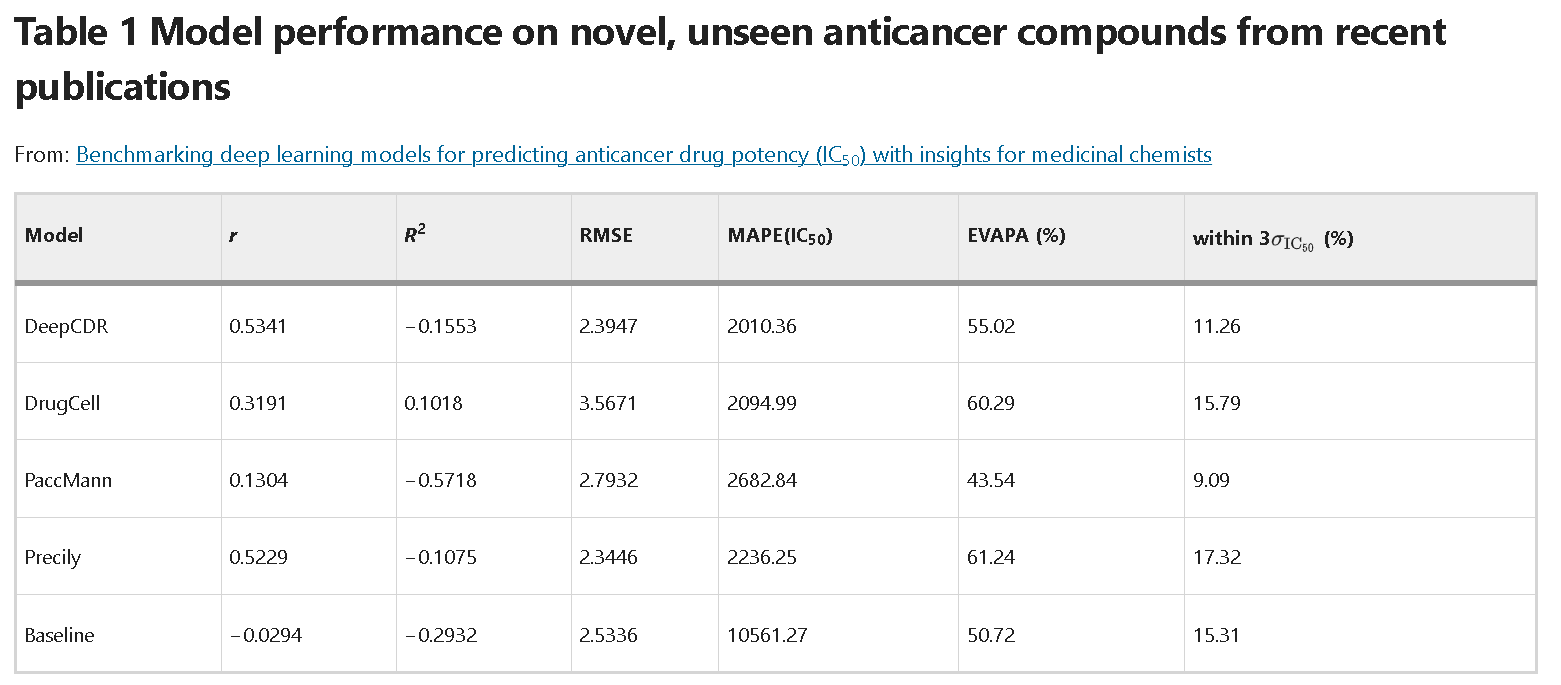
- 화합물의 입체 구조(Stereochemistry) 실험:
- 입체 구조 정보가 포함된 Isomeric SMILES와 정보가 없는 Canonical SMILES 간의 IC50 예측 성능 차이를 비교함
- 2. 모델별 결과:
- DeepCDR & Precily: 입체 구조 정보 유무에 따른 성능 차이가 거의 없거나 일관성이 없음. (영향을 안 받음)
- DrugCell: 입체 구조 정보(Isomeric)를 줬을 때 성능이 좋아짐.
- PaccMann: 특이하게도 입체 구조 정보가 추가되면 오히려 정확도가 떨어짐.
- DrugCell이 입체 구조를 잘 반영하는 이유는 Morgan fingerprint 방식을 사용하기 때문임. 이 방식은 분자의 입체적 특징을 효과적으로 포착해서 모델이 약물을 더 잘 이해하도록 도움
- 입체 구조 정보가 포함된 Isomeric SMILES와 정보가 없는 Canonical SMILES 간의 IC50 예측 성능 차이를 비교함
- GDSC 프로토콜에 따라, 새로운 약물에 대해 실험하여 얻음.
5. Take away
- Isomeric SMILES
- to the target pathways of compounds
- Four Lipinski parameters, namely molecular weight (MW), lipophilicity (clogP), number of hydrogen bond donors (HBD), and number of hydrogen bond acceptors (HBA), along with rotatable bond count (RotB) and the fraction of sp3-hybridized atoms (Fsp3)
- r(피어슨 상관계수)값은 경향성만 보기 때문. 실제값이 커질 때 예측값도 커지기만 하면 r은 높게나온다.
